云监控
1. 环境要求
对执行系统所在服务器要求,如下:
(1)能访问以下网址
| 平台服务 | 网址 |
|---|---|
| 监控浏览服务 | http://monitor.ework360.com |
| 云平台服务 | http://cloud.yindangu.com |
(2)能与以下服务端口连接通信
| 端口 | IP地址 及 端口 |
|---|---|
| TCP端口 | 47.106.142.219:9994 |
| UDP端口 | 47.106.142.219:9995 |
| UDP端口 | 47.106.142.219:9996 |
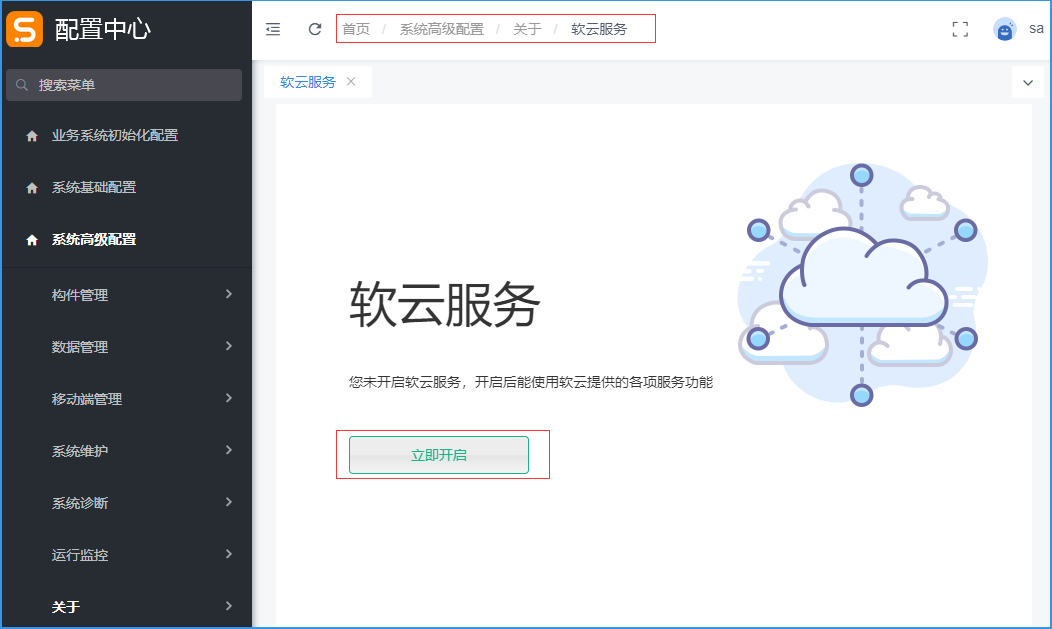
2. 开启软云服务
软云服务,是所有云服务的基础,开启后才能使用软云提供的各项服务功能,包括云监控服务、WE B报表服务等。
vteam云项目的执行系统默认已自动开启了。
在配置中心中(例如:http://ServerIP:Port/system/settings),打开软云服务。
访问目录:配置中心 → 系统高级配置 → 关于 → 软云服务

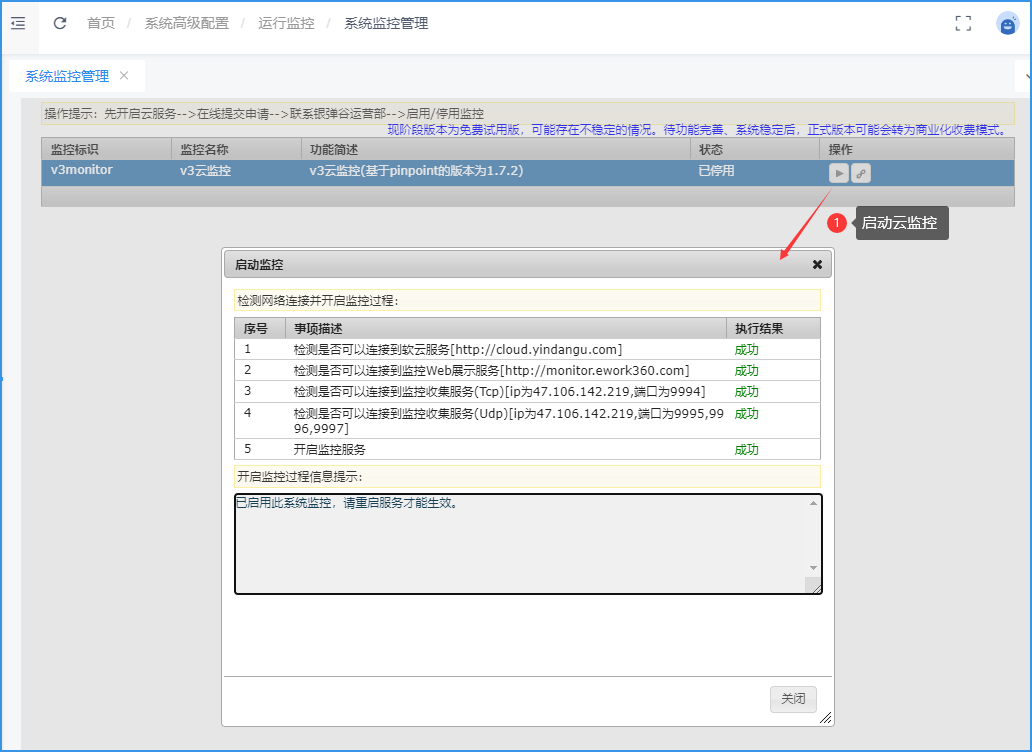
3. 启用监控
开启软云服务之后,需要开启V3云监控。
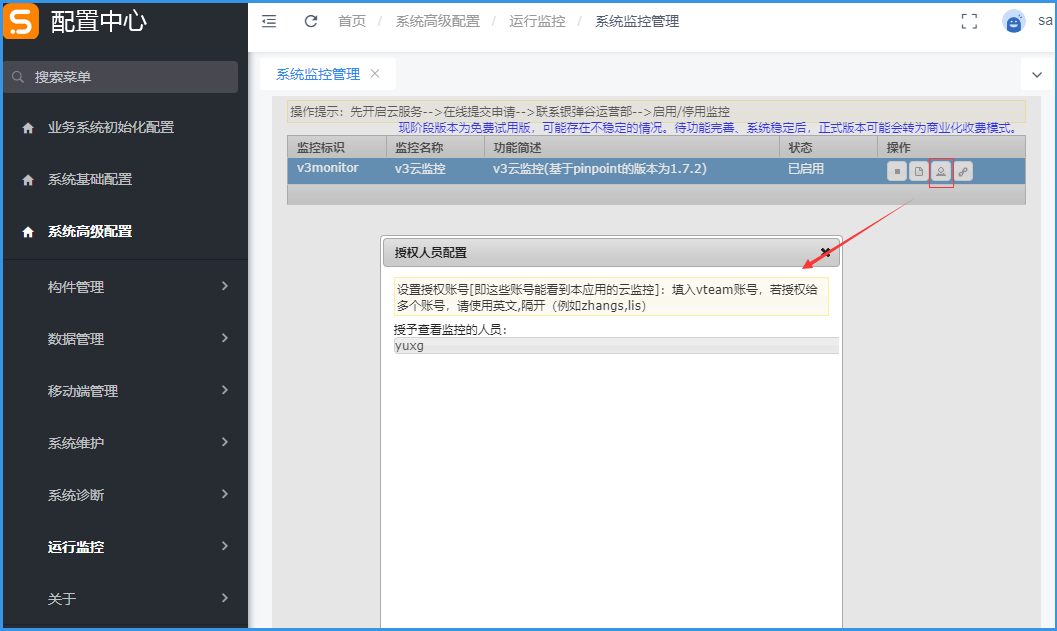
访问目录:配置中心 → 系统高级配置 → 运行监控 → 系统监控管理
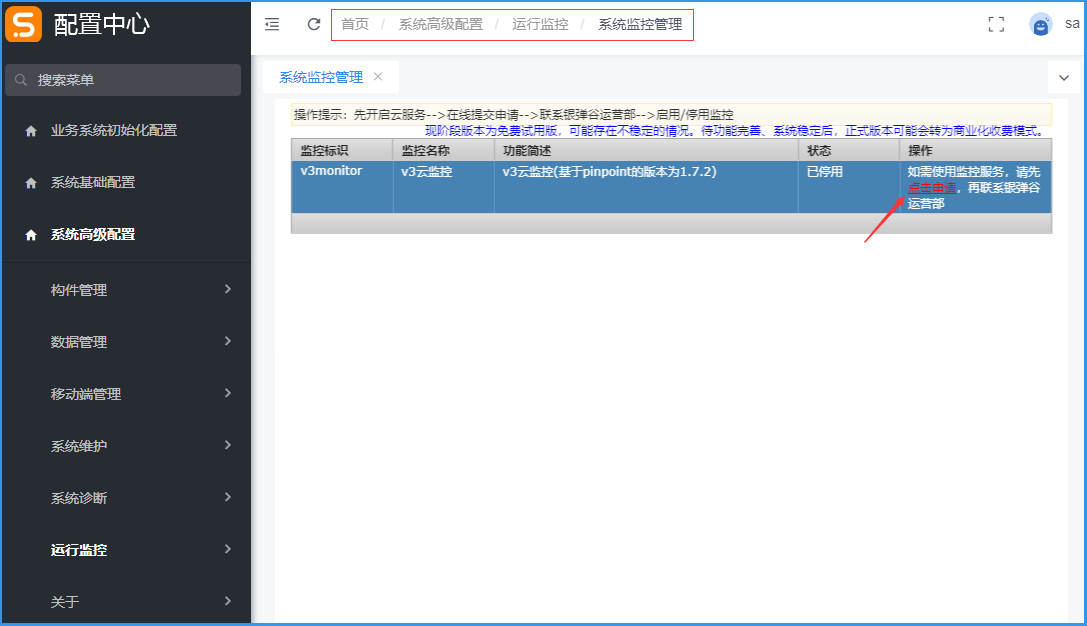
点击申请后,请联系银弹谷运营部,进行审核通过后才能启用监控。
(现阶段版本为免费试用版,可能存在不稳定的情况。待功能完善、系统稳定后,正式版本可能会转为商业化收费模式)
联系方式
- 企业微信:于晓钢
- 银弹谷V平台技术发烧友QQ群:同望银弹谷-于晓钢
- 电子邮件:vdept@toone.com.cn
注意:为了银弹谷内部人员方便使用,银弹谷内部人员账号启动的执行系统服务,点击申请后,会自动审核通过的,不需要人工联系进行审核的。
若执行系统是在外部 Web 容器启动的,例如
tomcat,weblogic等等。那么就要在 web 容器启动的脚本上增加
-javaagent配置。info若是执行系统用内置容器 V3Runtime\bin\startup.cmd 启动的,以下的内容可忽略。
(1)按上面步骤开启监控。
(2)在执行系统所有目录下 V3Runtime\bin\setOptions.cmd,打开此文件,找到
-javaagent字样的属性值拷贝此属性值,如下:
(3)拷贝出来的值,如下:
-javaagent:conf\setting\itop\monitor\thirdpart\pinpoint\1.7.2\pinpoint-bootstrap-1.7.2.jar
-Dpinpoint.agentId=wCskgHeHJGg7e57FdoMJtQ__ -Dpinpoint.applicationName=taoyzTomcat根据执行系统所在的目录,修改
-javaagent字样的属性值:-javaagent:D:\vBoxApp\appServer0205\V-AppServer\WEB-INF\conf\setting\itop\monitor\thirdpart\pinpoint\1.7.2
\pinpoint-bootstrap-1.7.2.jar-Dpinpoint.agentId=wCskgHeHJGg7e57FdoMJtQ__ -Dpinpoint.applicationName=taoyzTomcat(4)若在 tomcat 环境,以 window 为例:
在 tomcat 的 catalina.bat 文件里,JAVA_OPTS 增加拷贝出来补全路径后的
-javaagent内容,如下:set JAVA_OPTS=%JAVA_OPTS%-javaagent:D:\vBoxApp\appServer0205\V-AppServer\WEB-INF\conf\setting\itop\monitor\thirdpart\pinpoint
\1.7.2\pinpoint-bootstrap-1.7.2.jar-Dpinpoint.agentId=wCskgHeHJGg7e57FdoMJtQ__-Dpinpoint.applicationName=taoyzTomcat(5)若在 weblogic 环境,以 linux 为例:
在 weblogic 的 startWebLogic.sh 文件里,JAVA_OPTIONS 增加拷贝出来补全路径后的
-javaagent内容,如下:JAVA_OPTIONS="${SAVE_JAVA_OPTIONS}-javaagent:/root/v3/RunContent/WEB-INF/conf/setting/itop/monitor/thirdpart/pinpoint/1.7.2
/pinpoint-bootstrap-1.7.2.jar-Dpinpoint.agentId=MlHcnPI7bAwYecL0hklyVg__-Dpinpoint.applicationName=taoyzTestXXX"(6)其它容器同理,在启动脚本上加上
-javaagent的内容。(7)容器启动脚本上加上
-javaagent后,需要重启容器( tomcat 或 weblogic 等等)才能生效。

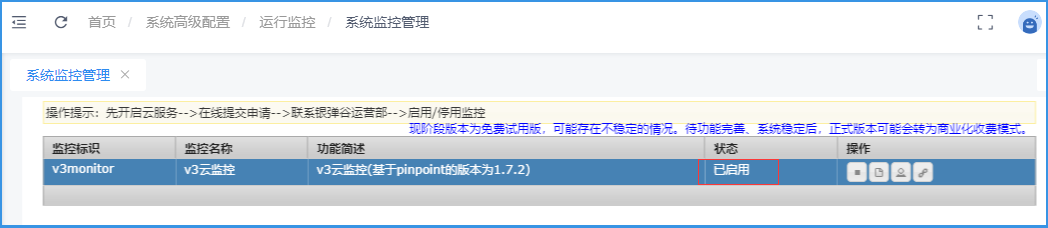
4. 查看监控数据以及部分监控功能
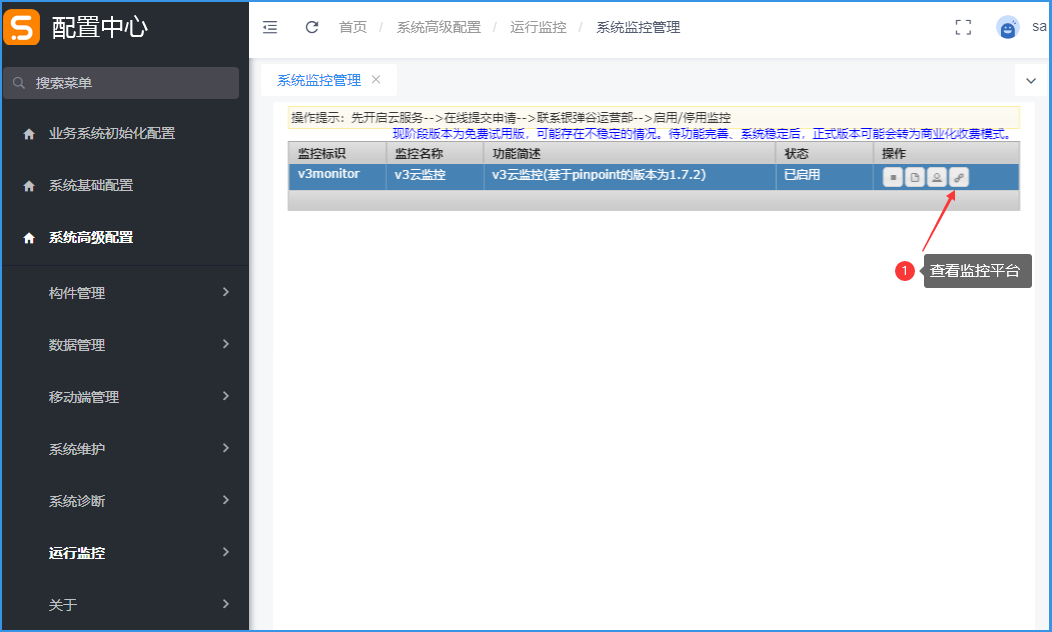
开启V3云监控后,可以查看监控平台。
访问目录:配置中心 → 系统高级配置 → 运行监控 → 系统监控管理
方法一:在系统监控管理中,直接点击【查看监控平台】按钮。
访问:访问 http://monitor.ework360.com 监控Web服务地址,使用启动执行系统服务时的用户名密码登录,即可。
有2种方式(点击蓝色按钮切换)。
(1) 直接使用平台预设的时间节点
REALTIME:实时请求数据
Last 5m:最后5分钟请求数据
20m:最后20分钟请求数据

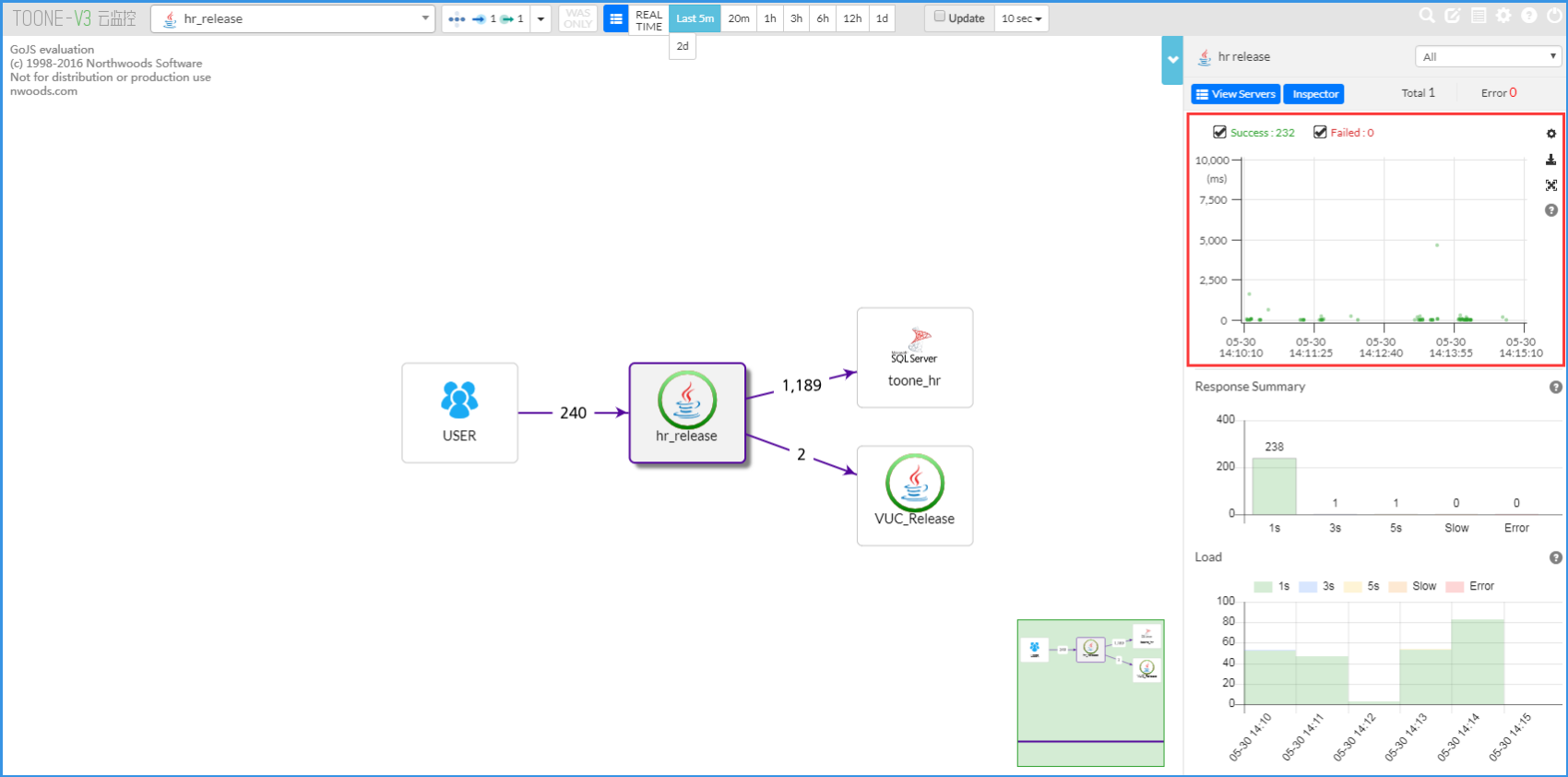
(2)自定义开始时间点和结束时间点

选择中间节点,查看右上角相关信息。
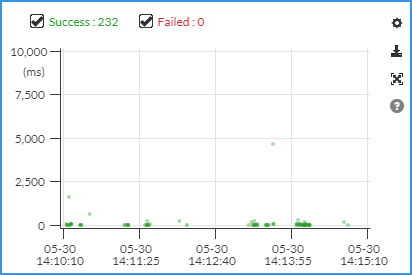
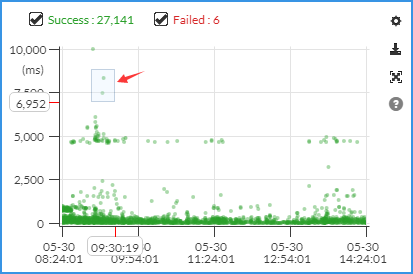
- 2个图例项(绿色
Success是成功,红色Failed 是失败); - 纵坐标:请求的耗时,单位是毫秒;
- 横坐标:时间,根据你选的时间段显示。
第一步:首先选时间段,在点状图上,选中耗时高的请求。
第二步:进入请求详情页面。

- (1)成功请求一
- (2)成功请求二
- (3)请求失败
选第一条请求,首先关注的是本身的耗时(列名是 self ),找到耗时最高的那条数据。
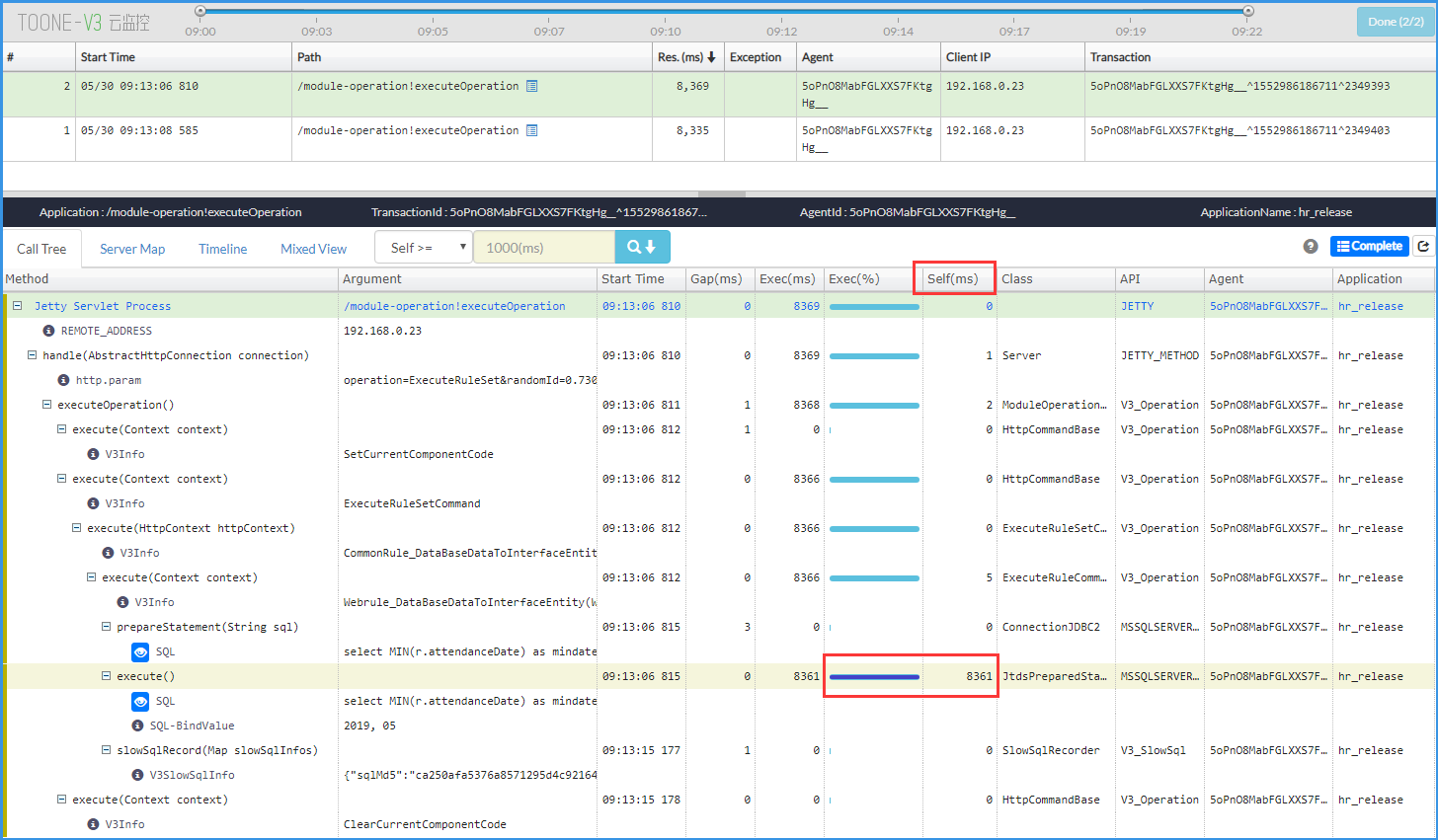
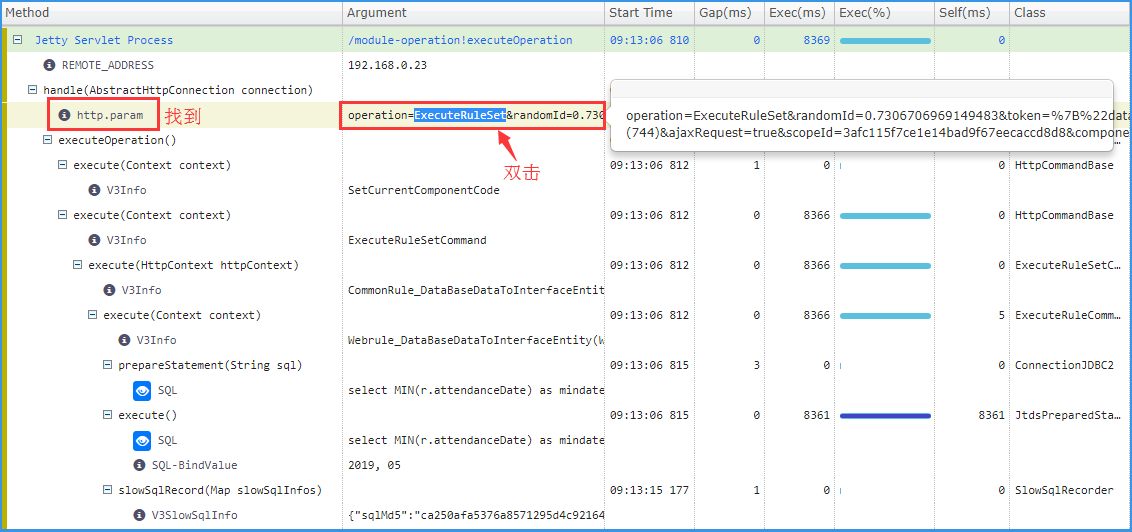
找到对应的父节点,标识为 “http.param” ,双击查看 Argument 。
在详情里,可以确定2个信息,构件编码 componentCode 、窗体编码 windowCode。
分析这个耗时为 8361 毫秒的请求。
可以看出,这是一条 SQL 的运行耗时记录。
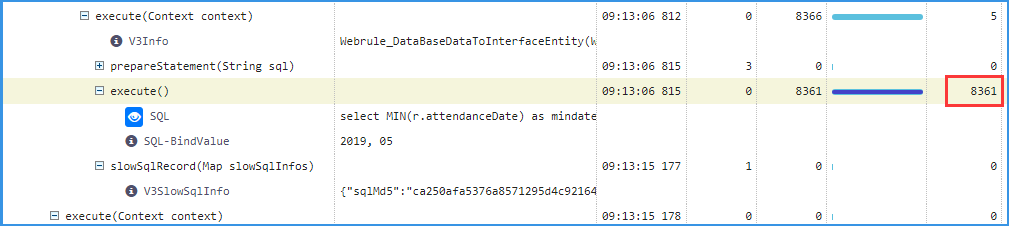
同样,在标识为 “SQL”,双击查看 Argument。
详情里,看出这是一条 SQL 语句,下面标识为 “SQL-BindValue” 的 “2019,05 ” 是它的 2 个参数。

在标识为 “V3SlowSqlInfo” 的详情中,是这条慢 SQL 替换参数后的语句。
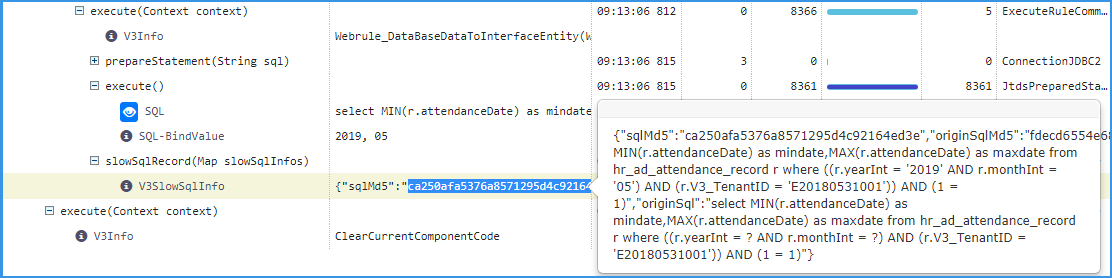
处理方式:得到这个语句之后,就可以分析这段 SQL 语句是否可以优化,提高它的运行速度。
下面,看另外一种情况,这里有一个总耗时 11162 毫秒的请求。
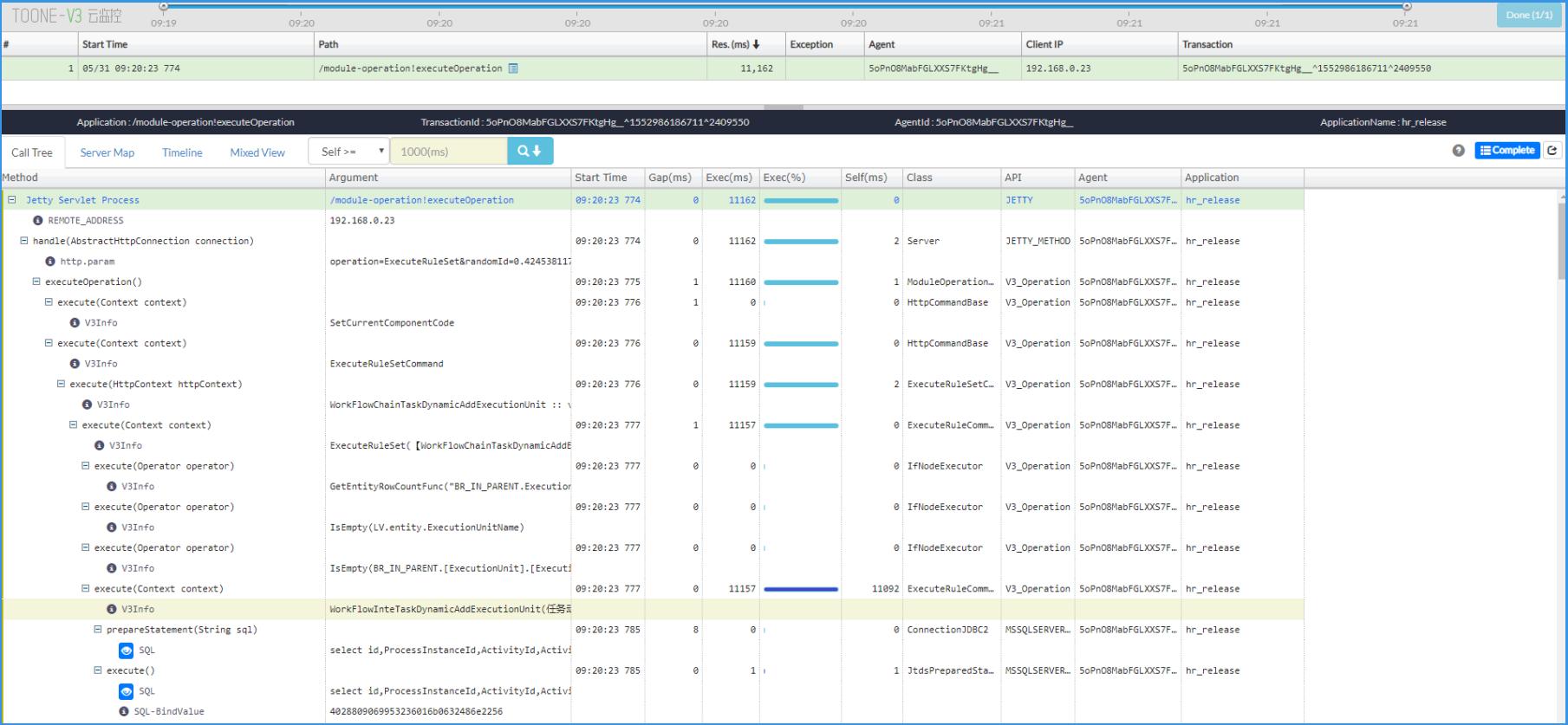
它的耗时主体,就不是 SQL 了,而是一个 API 。
构件编码和窗体编码的获取方式,同上。

查看 Argument ,可以得到:
| 参数 | 值 |
|---|---|
| API编码 | WorkFlowChainTaskDynamicAddExecutionUnit |
| API名称 | 任务动态增加执行人 |
| 所属构件 | vbase_流程管理API(vbase_workflow_api) |
| API文档 | 《vbase_流程管理API_vbase_workflow_api_API接口说明.xls》 |

处理方式:有经验的配置人员,可以根据这些信息,去寻找它并尝试优化它,否则就记录下来反馈给V平台部。
接下来,看错误请求,就是图例项为红色 Failed 的。
取消绿色 Success 的勾选,只选择失败的。

方式同上,会收集到很多失败的请求。
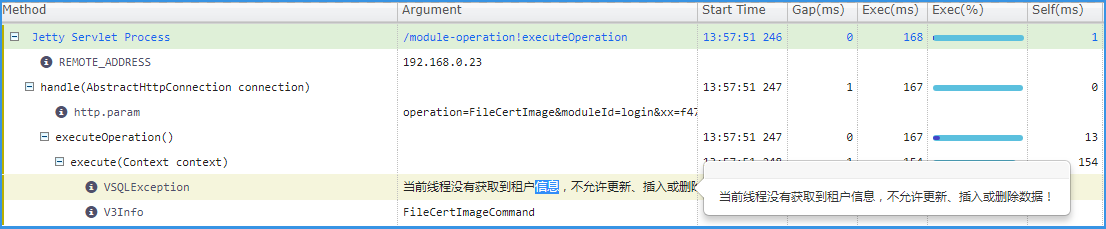
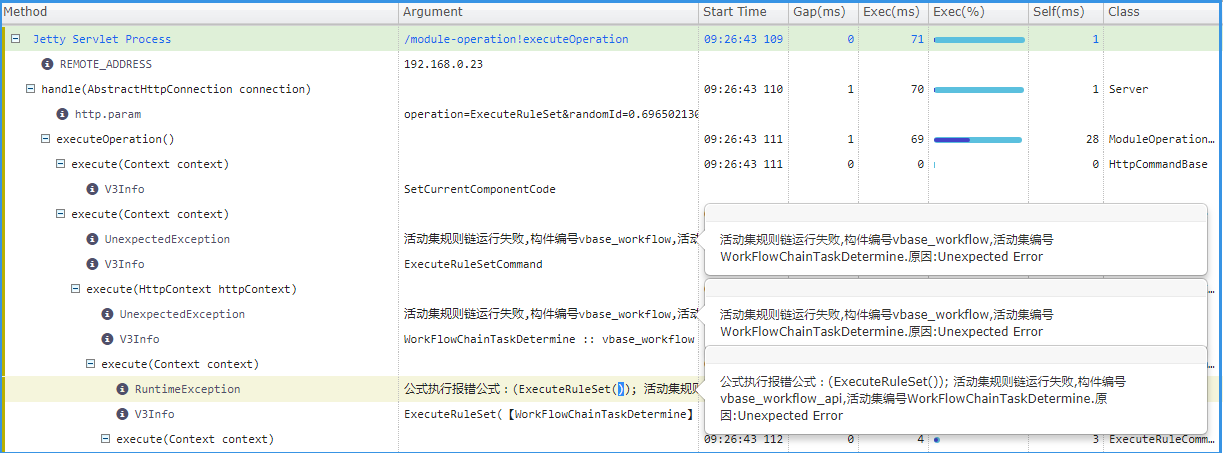
处理方式:有经验的配置人员,可以根据错误提示,去寻找它并尝试解决它,否则就记录下来反馈给V平台部。
点击右上角的【lnspector】按钮。
进入监控详情页面之后,点击左边红框处的服务实例标识(如果是集群的时候会有多个实例标识)。
监控内容包括有内存、cpu、响应时间等等的按时间范围的统计图。
重点关注的是图中标记三处:

堆栈内存使用情况
系统CPU使用率
响应时间
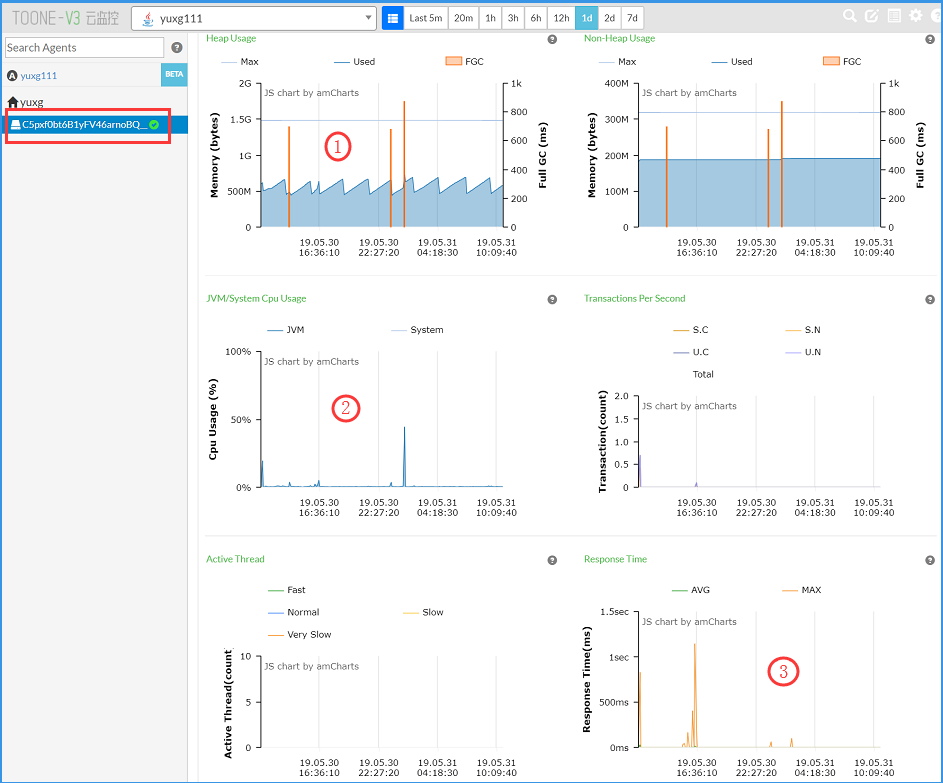
(1)内存监控
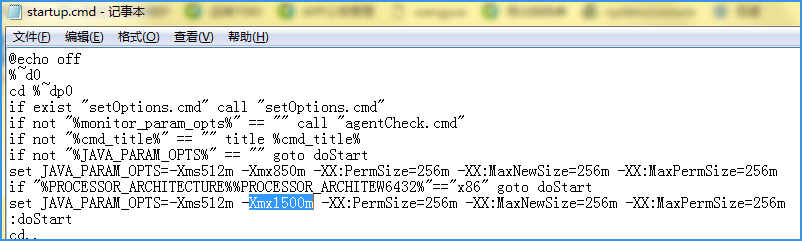
Max 1.5GB,就是服务 startupNaNd 批处理里设置的最大内存,图中是一条横线。
蓝色折线,为当前时间点使用内存情况。
橙色竖线,为当前时间点回收内存情况。
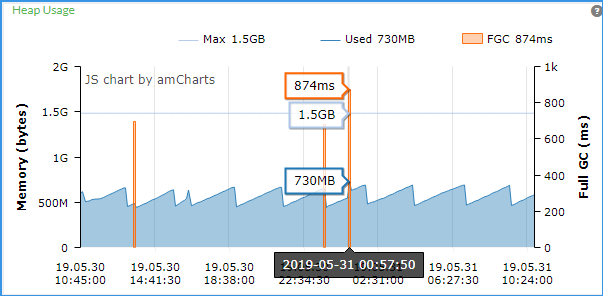
需要重点关注的是,当前使用的内存,超过预设最大内存的情况。
处理方式:根据实际情况,分析是否服务的最大内存太小,不满足项目需求,可以增加服务设置的内存。
如果分析是不正常的内存使用暴涨,并超过服务设置内存,记录下来反馈给V平台部。
还可以设置监控预警,做到早发现早处理。
(2)系统CPU使用率监控
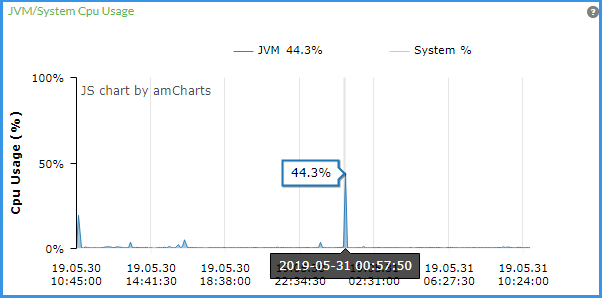
需要重点关注的是,当前CPU使用率的情况,是否过高。
处理方式:根据实际情况,分析CPU使用率的峰值是否正常,如果不正常致使CPU100%满载负荷,记录下来反馈给V平台部。
还可以设置监控预警,做到早发现早处理。
(3)响应时间监控
橙色MAX:最大响应时间(单位:毫秒)。
绿色AVG:平均响应时间(单位:毫秒)。
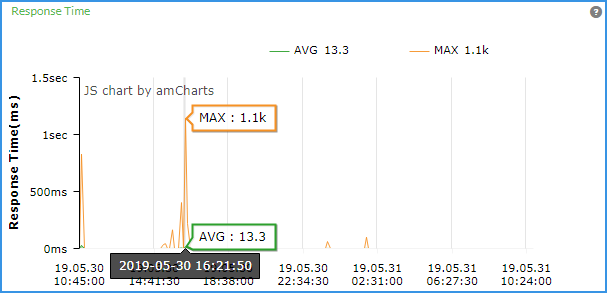
需要重点关注的是,当前响应时间是否过长。
处理方式:根据实际情况,分析响应时间的MAX是否过长,如果响应时间过长导致假死机状态,记录下来反馈给V平台部。
还可以设置监控预警,做到早发现早处理。
在监控平台首页,点击右上角的“慢sql统计”按钮。
打开 “慢sql统计” 页面
输入查询统计条件后,点击“执行查询”按钮


耗时大于:预设值为 5000 毫秒
开始时间:预设值为昨天此时
结束时间:预设值为当前时间
sql 类型:全部、
select、insert、update、delete
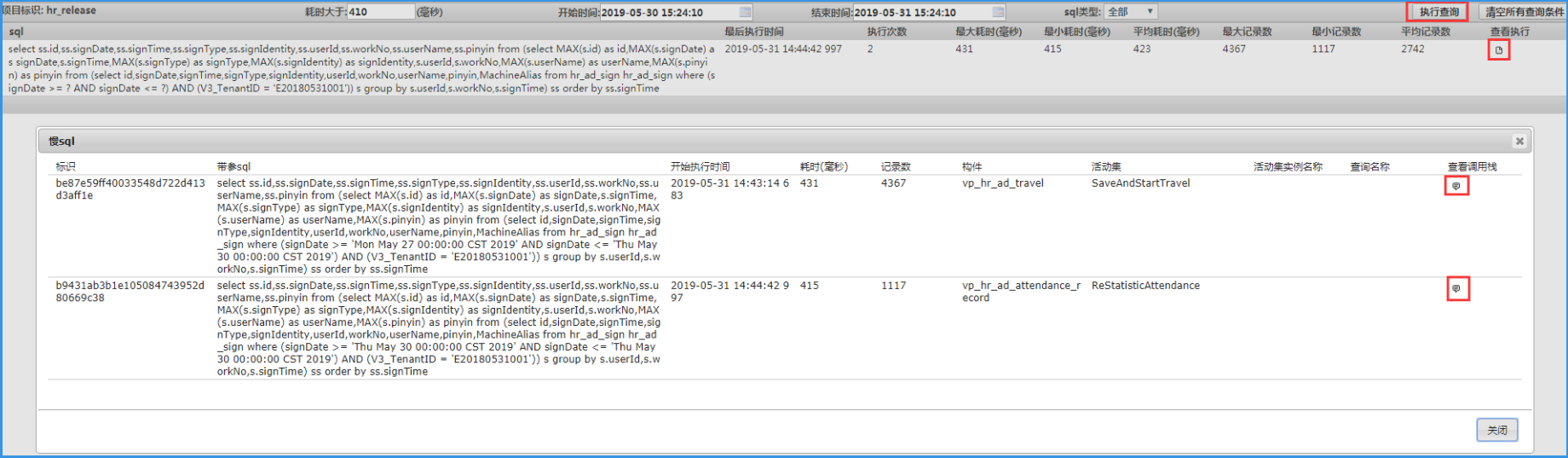
可以看到此时间段符合属于慢 sql 的统计情况。
包括有:最后执行时间、执行次数、最大耗时(毫秒)、最小耗时(毫秒)、平均耗时(毫秒)、最大记录数、最小记录数、平均记录数等等信息。
点击【查看执行】详细,可以看到慢 sql 每次执行的耗进情况,所在哪个构件,哪个活动集,哪个查询等信息。
更详细的调用信息,可以点击【查看调用栈】来查看此sql的调用情况。
5. 对项目应用进行监控预警设置
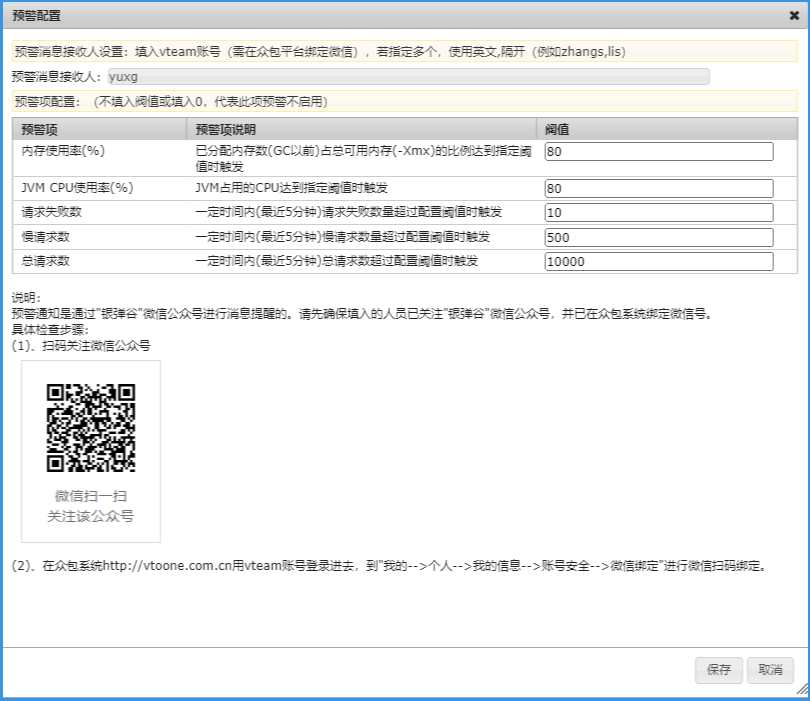
(1)设置预警项阀值
点击【预警配置】按钮,进行预警项阀值设置。
可修改默认阀值,填入信息推送的vstore账号(多个账号用逗号隔开),然后保存即可。
注意填入阀值的预警项被启用,不填入阀值的预警项不启用。
预警项设置完成,当达到预警项的阀值时,对 vstore 账号进行信息推送。
(2)预警项介绍
目前云监控的预警项一共分5种,其中的阀值请根据项目服务情况和服务器配置填写: a、内存使用率(%):已分配内存数(GC以前)占总可用内存(-Xmx)的比例达到指定阈值时触发。
b、JVM CPU使用率(%):JVM占用的CPU达到指定阈值时触发。
c、请求失败数:一定时间内(最近5分钟)请求失败数量超过配置阈值时触发。
d、慢请求数:一定时间内(最近5分钟)慢请求数量超过配置阈值时触发。
e、总请求数:一定时间内(最近5分钟)总请求数超过配置阈值时触发。
(3)预警通知
这个,就是当预警项超过阀值时,发送的“预警通知”。

同时开启定时诊断功能,主动被动结合,就能更好的监控服务系统的健康状况。
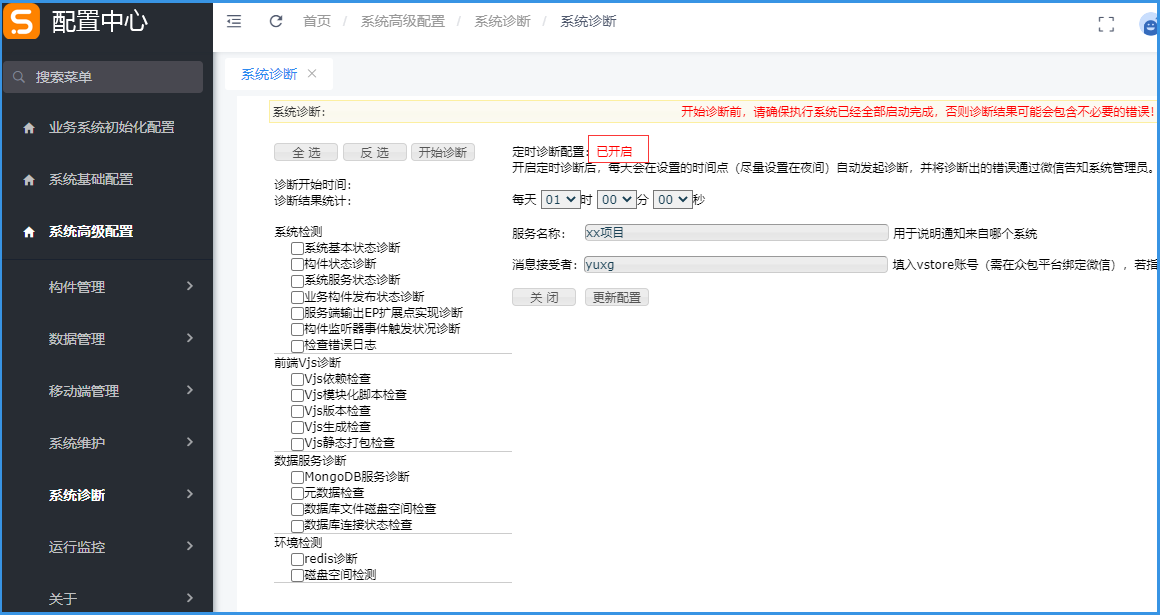
(1)开启步骤
访问目录:配置中心 → 系统高级配置 → 系统诊断 → 系统诊断
开启定时诊断后,每天会在设置的时间点(尽量设置在夜间)自动发起诊断,并将诊断出的错误通过微信告知系统管理员。
注意开始诊断前,请确保执行系统已经全部启动完成,否则诊断结果可能会包含不必要的错误!
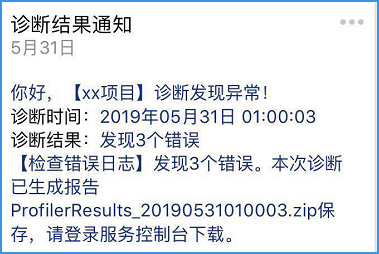
(2)诊断结果通知
定时诊断后时,发送的“诊断结果通知”,如下:
预警通知,是通过所填写的 vstore 账号所绑定的“银弹谷”微信公众号进行提醒。
所以,请先确保所填入的 vstore 账号已关注 “银弹谷” 微信公众号、并已在众包系统绑定微信。
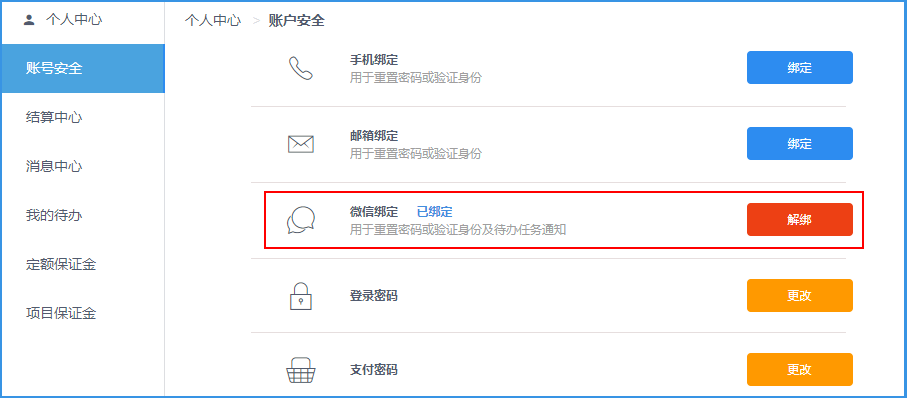
具体检查步骤:
(1)扫码关注微信公众号
(2)在众包系统 http://vtoone.com.cn 中用 vstore 账号登录,在 “我的 → 个人中心 → 账号安全” 进行微信扫描绑定。
绑定后,就可以接收到信息推送了。

6. 网络情况检查
使用 chrome 谷歌浏览器,按F 12 开发者工具,对请求时间分析。
功能强大,能够让看到网页加载的信息,默认情况下有八列:
Name:表示加载的文件名;Method:表示请求的方式;Status:表示状态码(200为请求成功,304表示从缓存读取);Type:表示文件的MIME Type的类型;Initiator:表示发出这个文件请求的发出者;Size:表示文件大小;Time:表示每个请求的总时长;Timeline:以图表的形式显示元素的请求和加载情况。
当然内容不仅仅限于以上8个,鼠标移到
Timeline的图表条上可以弹出一个菜单,可以查看更多内容。
Queueing:请求文件顺序的的排序浏览器有线程限制的,发请求也不能所有的请求同时发送,所以队列。
Stalled:是浏览器得到要发出这个请求的指令到请求可以发出的等待时间一般是代理协商、以及等待可复用的TCP连接释放的时间,不包括DNS查询、建立TCP连接等时间等。
DNS Lookup:时间执行 DNS 查找每个新域 pagerequires DNS 查找一个完整的往返。
Initial connection:建立 TCP 连接的时间就相当于客户端从发请求开始到 TCP 握手结束这一段,包括 DNS 查询 +Proxy 时间 +TCP 握手时间。
Request sent:上传时间请求第一个字节发出前到最后一个字节发出后的时间。
Waiting(TTFB):服务器处理和返回数据网络延时时间请求发出后,到收到响应的第一个字节所花费的时间 ( Time To First Byte) ,发送请求完毕到接收请求开始的时间。服务器优化的目的就是要让这个时间段尽可能短。
Content Download:下载时间收到响应的第一个字节,到接受完最后一个字节的时间。
重点关注:
Request sent、Waiting(TTFB)、Content Download。
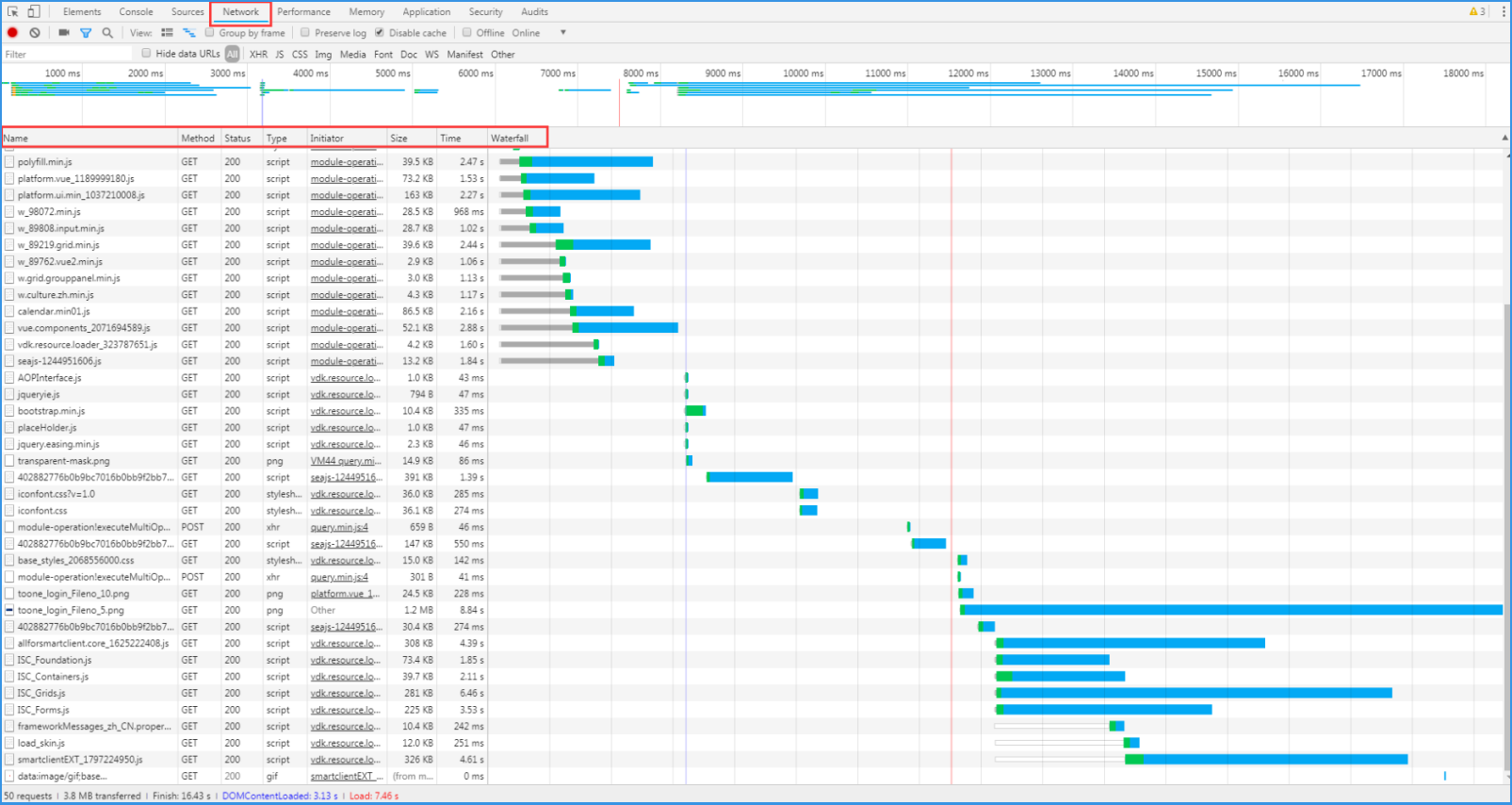
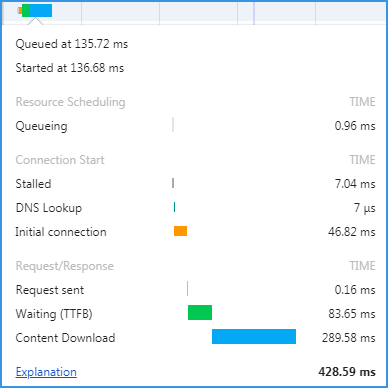
网络通畅与否,要看2个方面,1个是服务端,1个是客户端。其中任何一方面网络慢,都会影响整个系统打开的速度。
下面,以一个登录页面为例。
首先,用一个慢网络客户端,访问系统登录界面。
请求的总数量50个,请求的总大小3.8 MB,请求完成时间16.43 s,DOM树构建完成3.13 s,页面加载完毕7.46 s。
再看其中一个项,它是一张png图片,大小1.2MB,下载用时 8.84 s。
可以简单的计算一下大概的网络速率,1200KB/8.84s = 136 KB/s。
接下来,用一个快一点网络客户端,访问同一个登录界面。
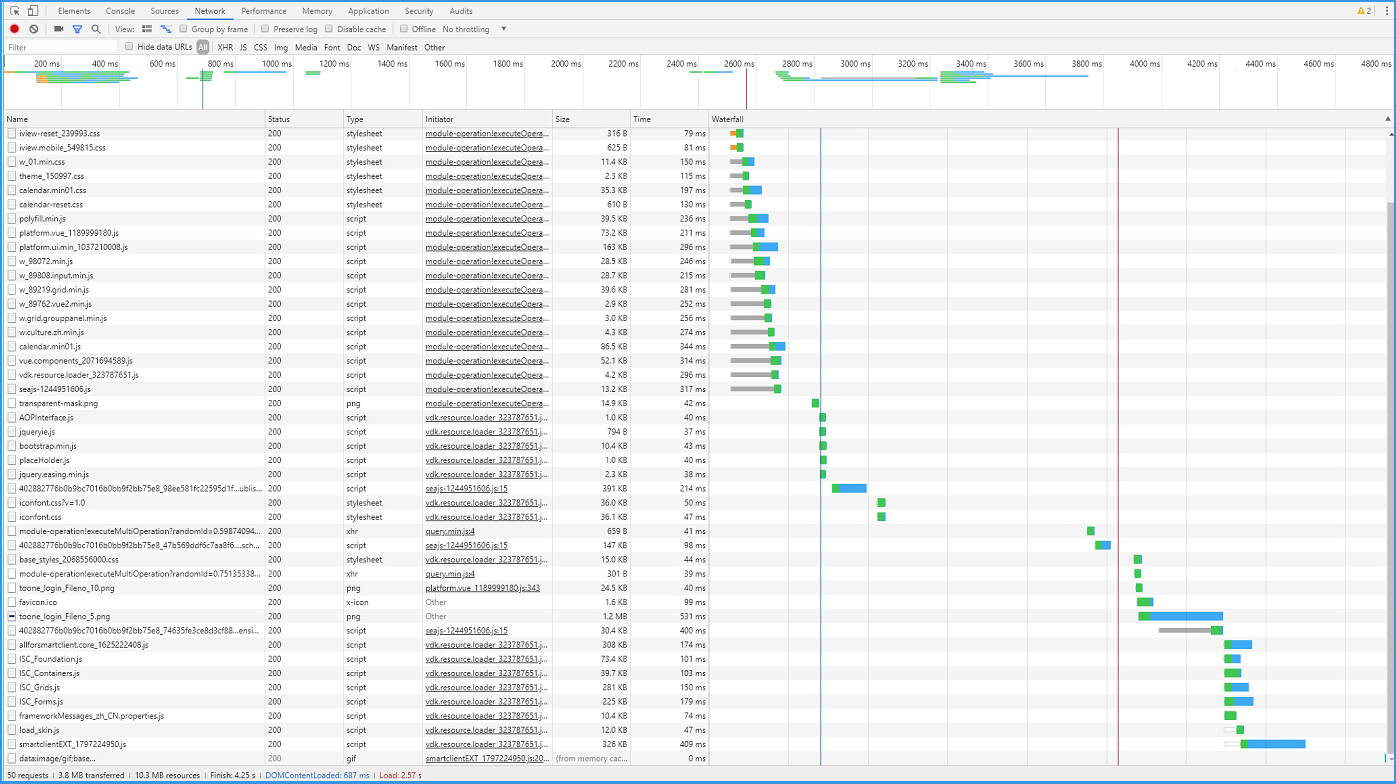
请求的总数量50个,请求的总大小3.8 MB,请求完成时间4.25 s,DOM树构建完成687 ms,页面加载完毕2.57 s。
还是看同一个项,png图片,大小1.2MB,下载用时 531 ms,再简单的计算一下大概的网络速率,1.2MB /0.531s = 2.26MB/s。
通过比较,可以确定是网络原因引起的加载页面慢。
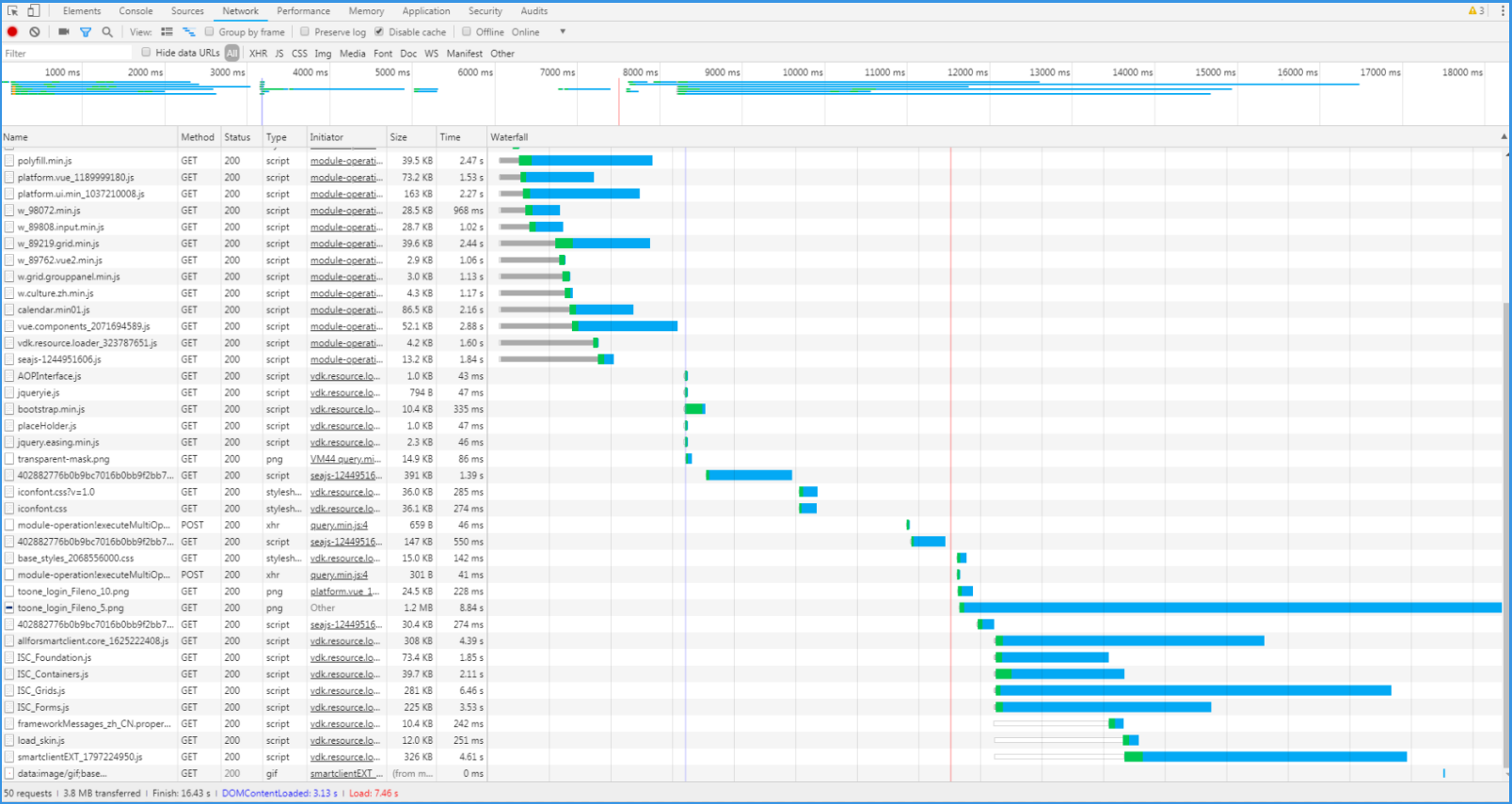

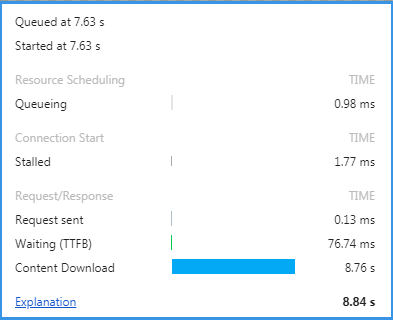

同是上面的例子,登录页面。
(1)网页窗体
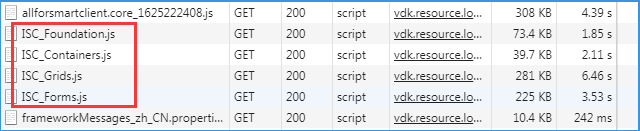
这4个ISC的js是普通窗体框架,证明这个登录页面,是用普通窗体或者里面含有普通窗体。
建议可以改为网页窗体来实现,加载速度会有提示。
(2)js压缩
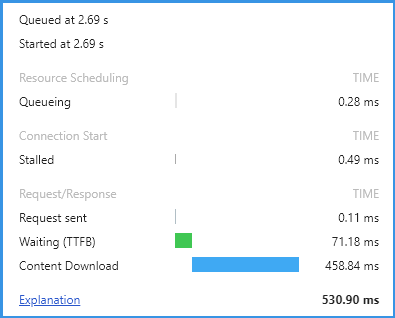
我们来看这几个js,他们的size都不大,但是下载用时都要1-2秒多。
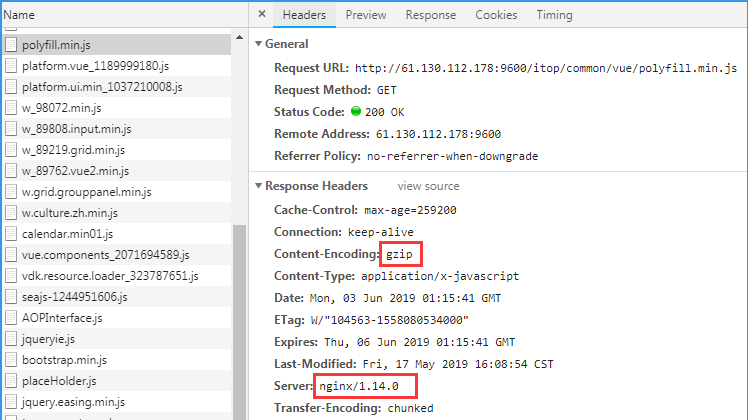
点击Name列里的项,在右边的Headers里,可以看到,
Content-Encoding:gzip
Server:nginx/1.14.0证明这个系统服务,已经使用了Nginx做了负载均衡服务,开启了GZIP进行压缩加速。
建议可以使用 Apache或者Nginx,并开启GZIP,提高速度,减少流量。
(3)缩小size
还以这个 1.2MB 的 png 图片为例。
建议是否可以修改分辨率,或者降低它的png模式,或者换成jpg格式,把这个图片的大小降到1MB以下。


这是一份真实案例,由于网络原因导致系统访问速度慢。
(1)获取信息
客户提出:系统访问速度很慢。
(2)查找原因
系统访问速度慢,无外乎 2 个原因(系统处理慢和网络访问慢)
首先,远程桌面连接执行系统所在服务器,在服务器的浏览器上直接使用 Localhost、内网IP、域名这 3 个地址访问系统,感受打开页面的速度,并通过 network 工具记录下所用耗时。
打开登录页面:2000 毫秒登录并
打开系统首页:3000 毫秒
然后,在自己的电脑上,使用域名访问系统,打开登录页面:6 秒
登录并打开系统首页:15 秒
注意还可以用IP访问看看,如果IP访问和域名访问,耗时相差比较大的话,怀疑就是域名映射方面存在问题。
(3)得到结论
经过对比,已经初步得出结论,网络问题非常严重。
(4)深入查找原因
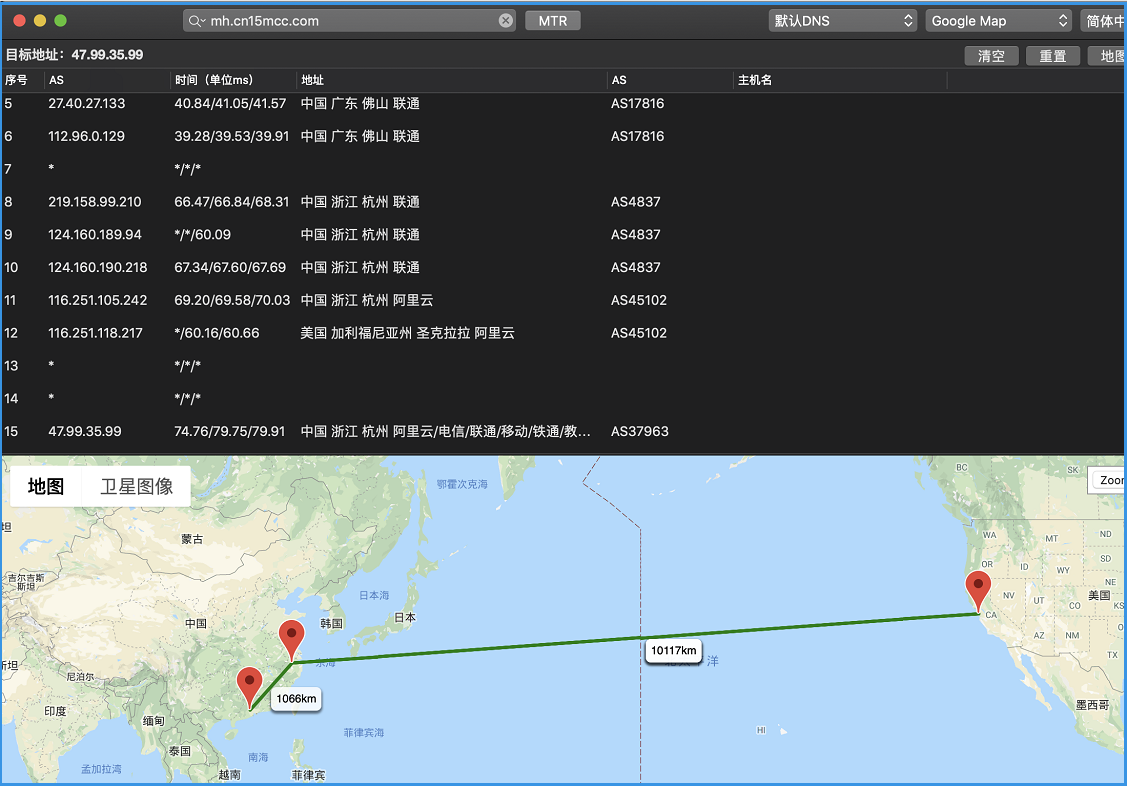
那么是哪个环节导致网络这么慢呢,我们可以用到一个路由追踪的工具,它可以列出经过的路由节点,当然这个工具也不是很精确,只能用来参考。
把域名录入,开始追踪。
可以看到,追踪的路由路径是先从广东到浙江,然后浙江到美国,最后又回来浙江。
兜兜转转一大圈。
这中间经历了重重的艰难险阻,速度肯定快不了。