概述
V-Data(数据分析平台)提供数据流功能,可达到专业级的数据处理效果,旨在让用户在数据分析、数据可视化制作前,能够对数据集进行易操作、低门槛、智能化的高效数据处理,使数据经过清洗、转换、装载后得到对终端业务人员更有效的数据集。
1. 数据流使用步骤
1.1 新建数据流
进入数据工厂的“数据流”界面,点击右上角的“创建”按钮,即可进入编辑界面。
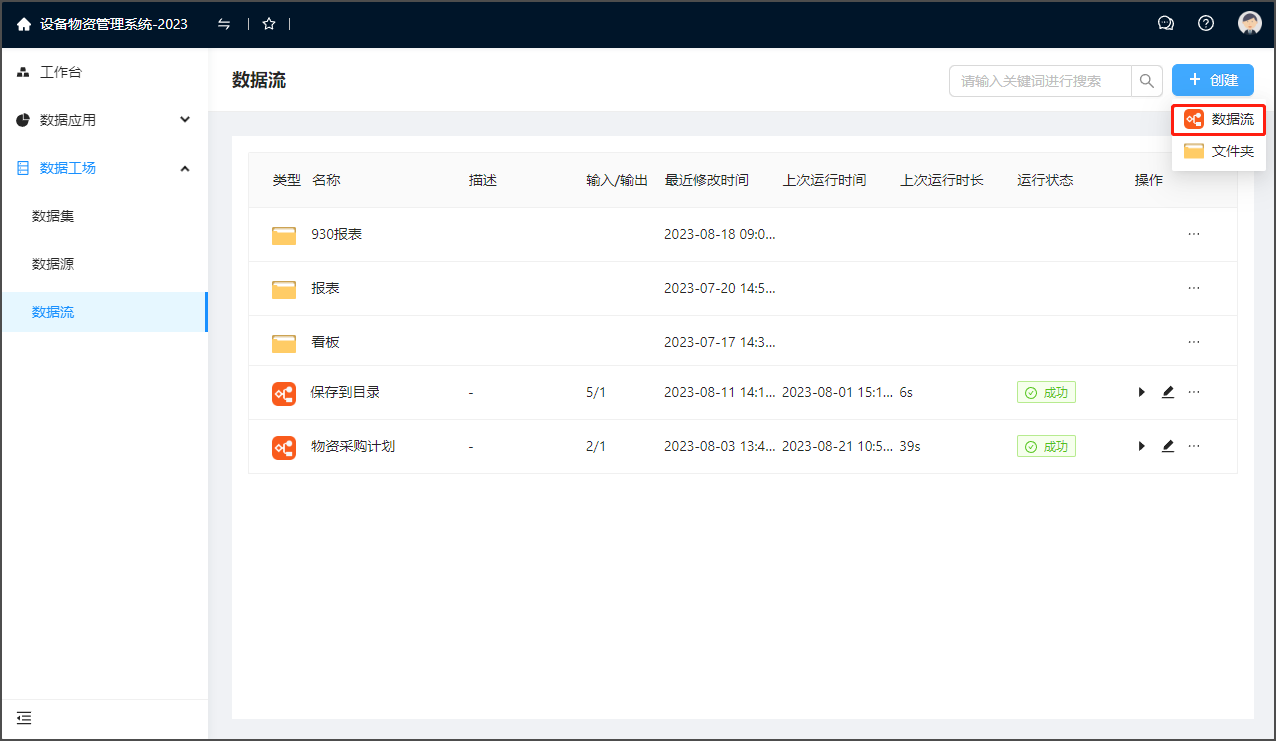
编辑页面概要如下图:
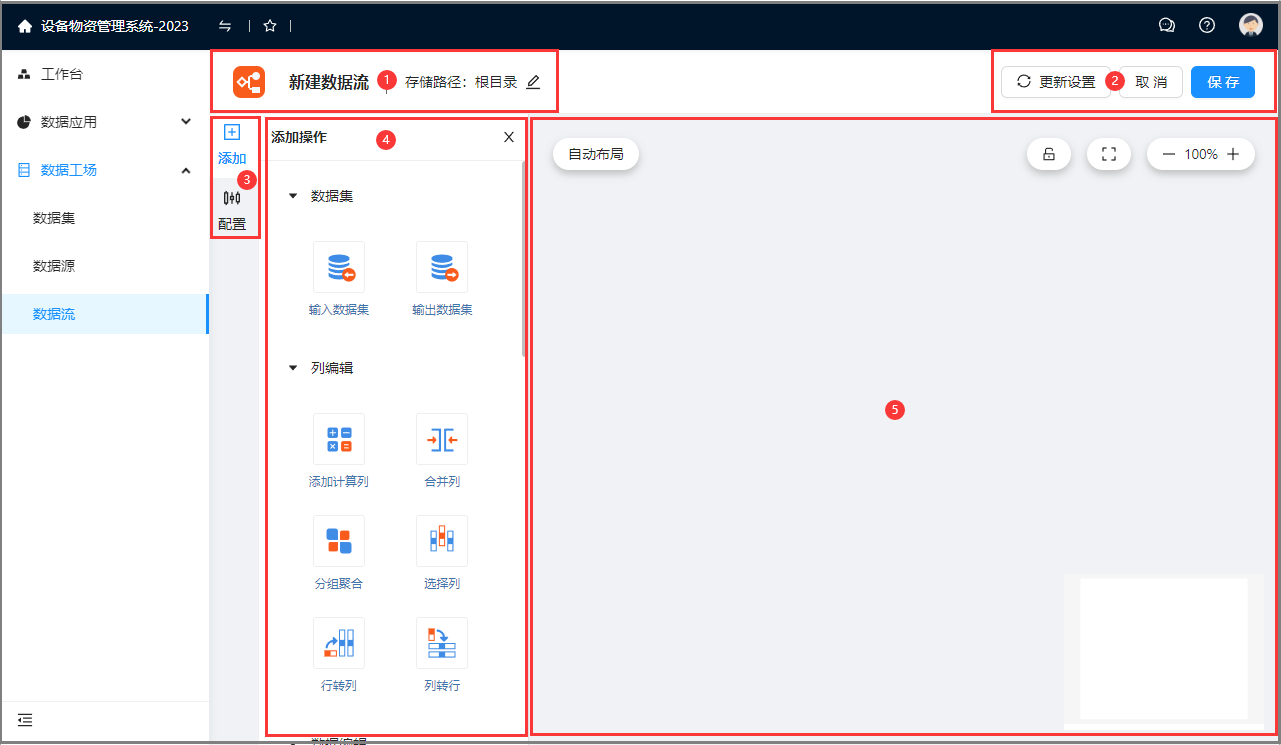
①编辑数据流名称、描述、存储路径:
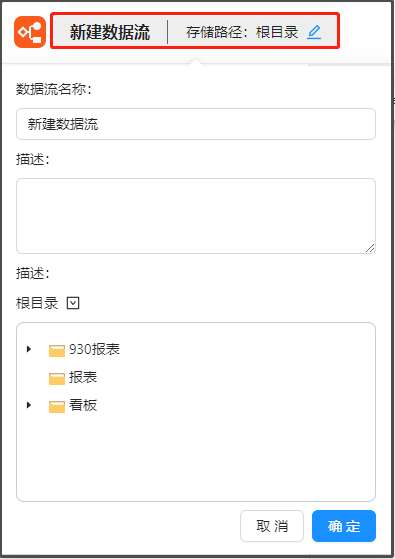
②更新设置、取消、保存
右上角的“更新设置”,即可选择更新方式为“手动”、“定时”或“勾选的数据集更新后”
- 选择“手动”时,可以通过默认和自定义进行超时设置。
- 选择“定时”时,可以设置更新时间、任务优先级、超时设置。
- 选择“勾选的数据集更新后”时,可以设置触发条件、任务优先级、超时设置。
“取消”:取消新建数据流/编辑操作。
“保存”:保存新建数据流/编辑操作。
③添加操作、编辑操作 视图切换
④添加操作区域
详见本文 1.3 添加操作 章节。
⑤编辑视图区域
1.2 添加操作
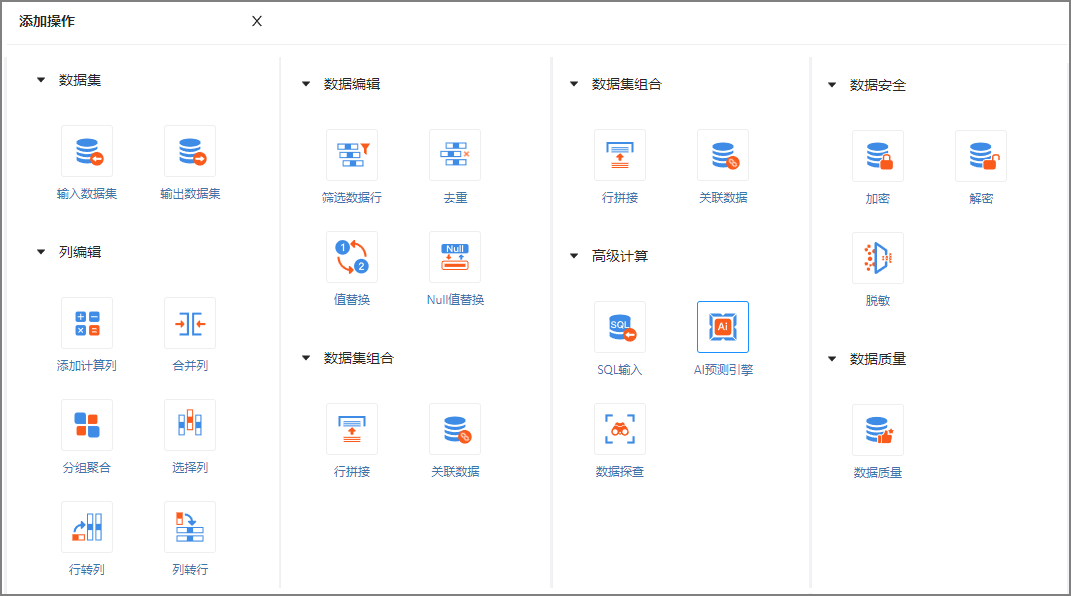
数据流界面左侧的“添加操作”分为7类:数据集、列编辑、数据编辑、数据集组合、高级计算、数据安全、数据质量 。将左侧的操作项拖拽至空白面板区,即可快捷进行具体操作。至少需要一个“输入数据集”和一个“输出数据集”才能构成一个完整的数据流。
实践案例:数据流案例
1.3 列表页操作
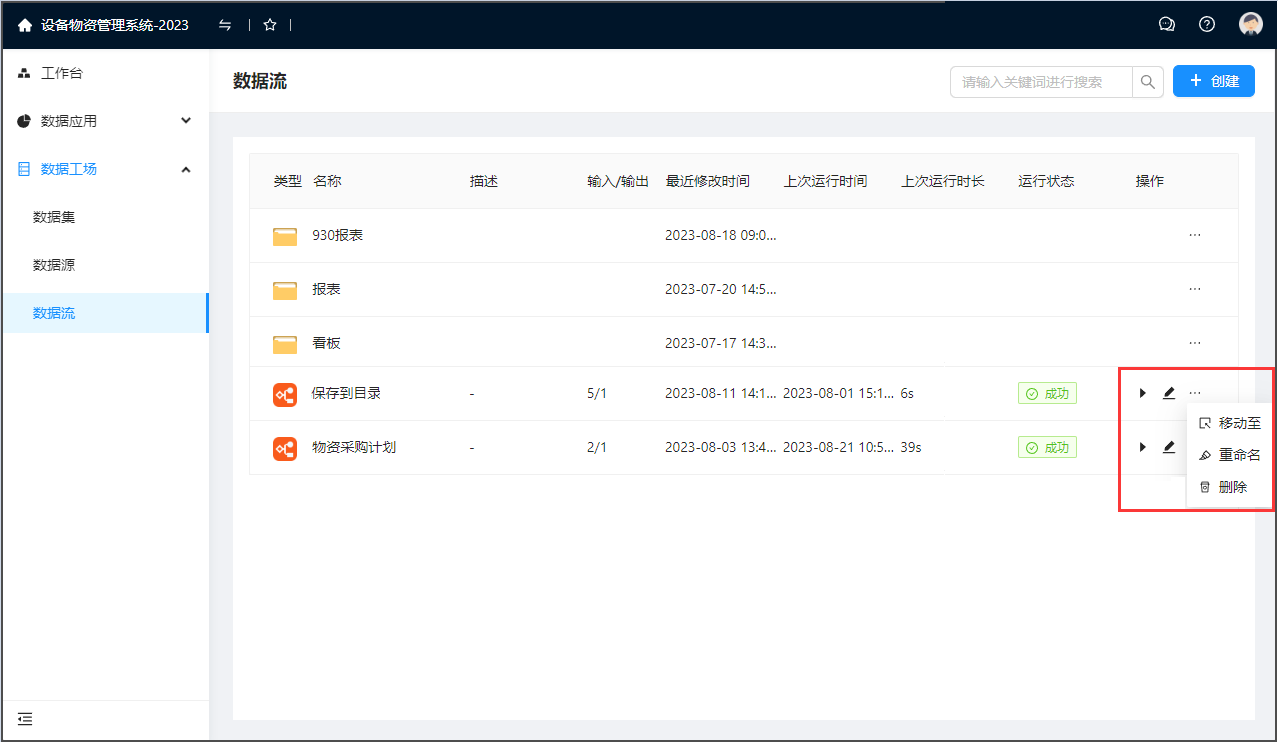
进入数据工场—数据流的目录列表页,可查看有对应权限的数据流,列表中有简要的信息如:“输入/输出”的数量、“最近修改时间”、“上次运行时间”、“上次运行时长”、“运行状态”以及运行、编辑等操作。点击最右侧的“···”按钮,可以显示具体的操作项:移动至、重命名、删除。
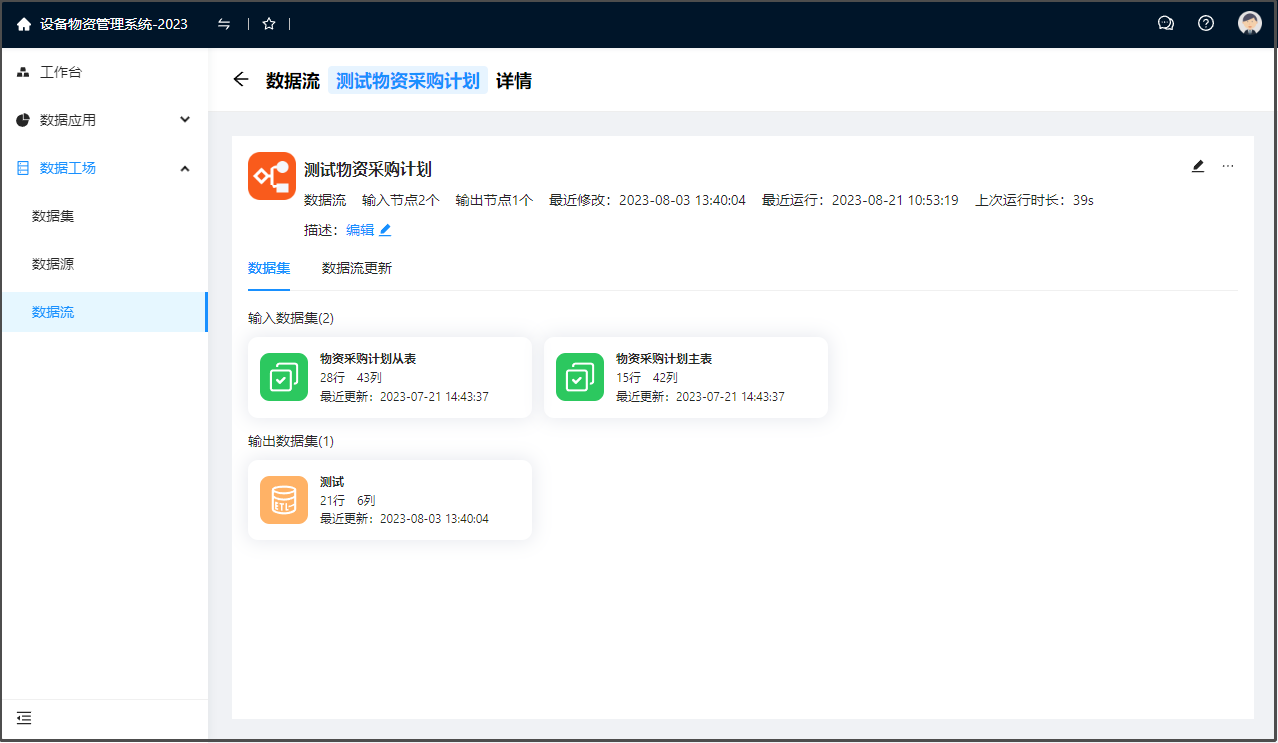
单击数据流行记录可查看详情:可查看数据流的输入节点、输出节点、最近修改、最近运行、上次运行时长、数据集、数据流更新等信息。也可以进行编辑、运行、移动至 和 删除等操作。
2. 应用场景
面对动辄几十亿行的库存数据,很多企业都会面对“留之累赘,弃之担忧”的尴尬。最常见的解决办法就是把每一天的全量快照数据都存下来,提供日期主键,然后开放给用户去查询。但这样实际上会保存很多不变的信息,对存储是极大的浪费;再者,设计不当还非常影响查询效率,拖垮数据库。举个例子:一家连锁超市企业,门店数3000,SKU数1000,如果存库存快照数据,每天就是300万,一年就是10个亿。如果要求能够查询5年的历史数据,那么就需要保存近50亿的历史快照数据。面对这类问题,V-Data(数据分析平台)的数据流 功能可以处理海量历史数据压缩存储与查询。既能满足反应数据的历史状态,又可以最大程度的节省存储空间,提高查询效率。